Supplementary Material 1
Model fit
We assessed the growth, survival, and recruitment rates by examining transitions between two measurements. While we fitted the growth and survival functions at the individual level, recruitment was evaluated at the plot level. Due to differences in measurement thresholds between the FIA and Quebec protocols, we only considered individuals with a dbh \(\ge\) 127 mm. Therefore, we quantified the ingrowth rate as the number of individuals crossing the 127 mm threshold. We included trees with at least two measurements over time to quantify growth and survival. Similarly, we used plots with at least two measurements over time for ingrowth. To simplify the model hierarchy, we did not incorporate temporal models. Instead, we treated two transition measurements for the same individual as independent information. The plot random effects partially accounted for the variation at the individual level, where different individuals with multiple measurements shared the same variation.
We fitted each of the growth, survival, and recruitment models separately for each species, using the Hamiltonian Monte Carlo (HMC) algorithm via the Stan software (version 2.30.1 Team and Others 2022) and the cmdstanr R package (version 0.5.3 Gabry, Češnovar, and Johnson 2023). We conducted 2000 iterations for the warm-up and sampling phases for each of the four chains, resulting in 8000 posterior samples. However, we kept only the last 1000 iterations of the sampling phase to save computation time and storage space, resulting in 4000 posterior samples. We assessed model convergence using Stan’s \(\hat{R}\) statistic, considering convergence achieved when \(\hat{R} < 1.05\). The complete code used for data preparation, model execution, and diagnostic analysis is hosted at https://github.com/willvieira/TreesDemography. Diagnostic reports for all fitted models, including information on model convergence, parameter distributions, prediction checks, \(R^2\), and other metrics, are available at https://willvieira.github.io/TreesDemography/.
Model comparison
We constructed the demographic models incrementally, starting from the simple intercept model and gradually adding plot random effects, competition, and climate covariates. While the intercept-only model represents the most basic form, we opted to discard it and use the intercept model with random effects as the baseline or null model for comparison with more complex models. We ensured the convergence of all these model forms, and comprehensive diagnostic details are available at https://github.com/willvieira/TreesDemography.
Our primary objective is to select the model that has learned the most from the data. We used complementary metrics to quantify the gain in information achieved by adding complexity to each demographic model. One intuitive metric involves assessing the reduction in variance attributed to likelihood and the variance associated with plot random effects. A greater reduction in their variance implies a greater information gain from model complexity. The following metrics are all derived from the idea of increasing predictive accuracy. Although we focus on inference, measuring predictive power is crucial for quantifying the additional information gained from including new covariates. The first two classic measures of predictive accuracy are the mean squared error (MSE) and the pseudo \(R^2\). We base these metrics on the linear relationship between observed and predicted demographic outputs. Finally, we used Leave-One-Out Cross-Validation (LOO-CV), which uses the sampled data to estimate the model’s out-of-sample predictive accuracy (Vehtari, Gelman, and Gabry 2017). LOO-CV allows us to assess how well each model describes the observed data and compare competing models to determine which has learned the most from the data.
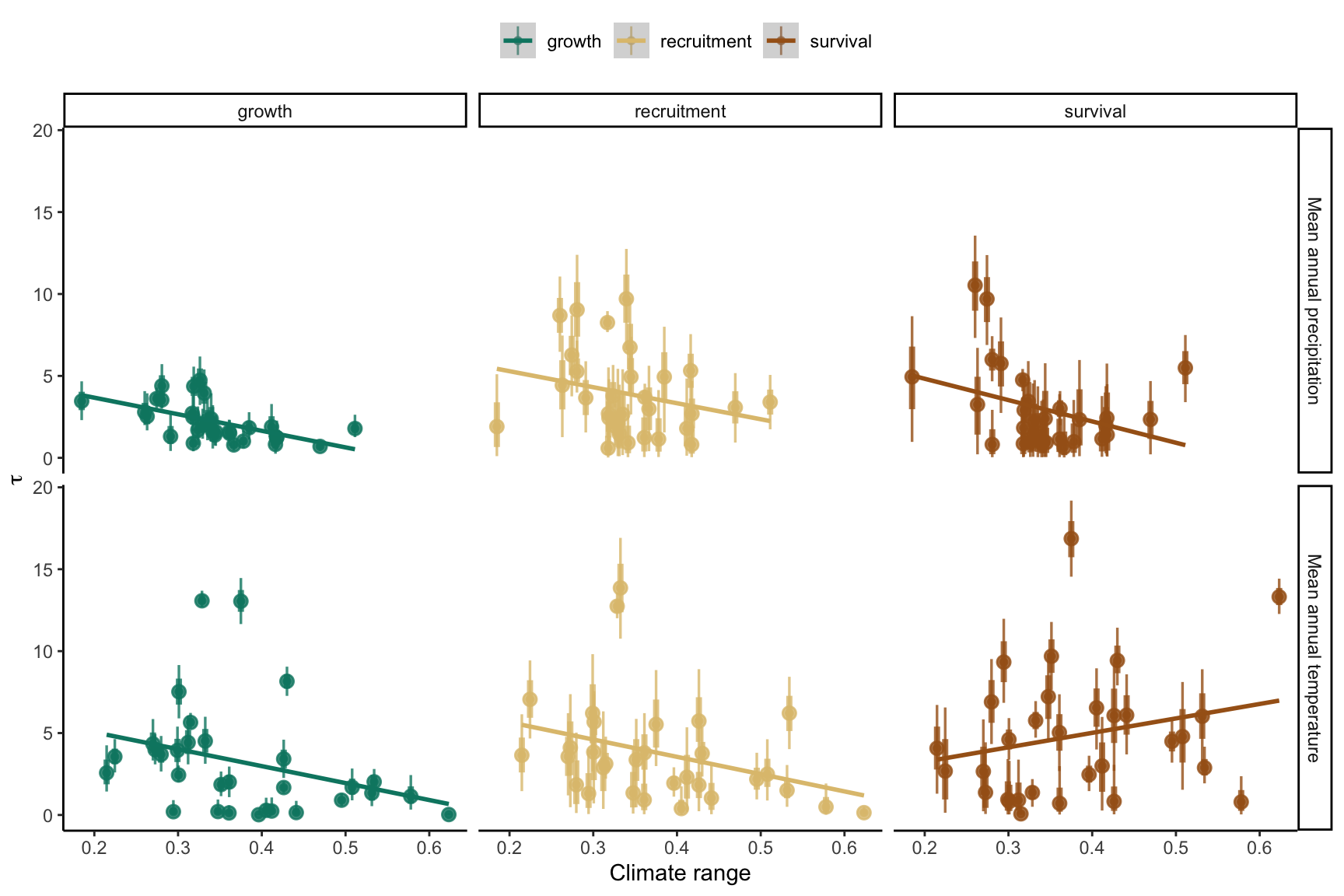
Parameter variance
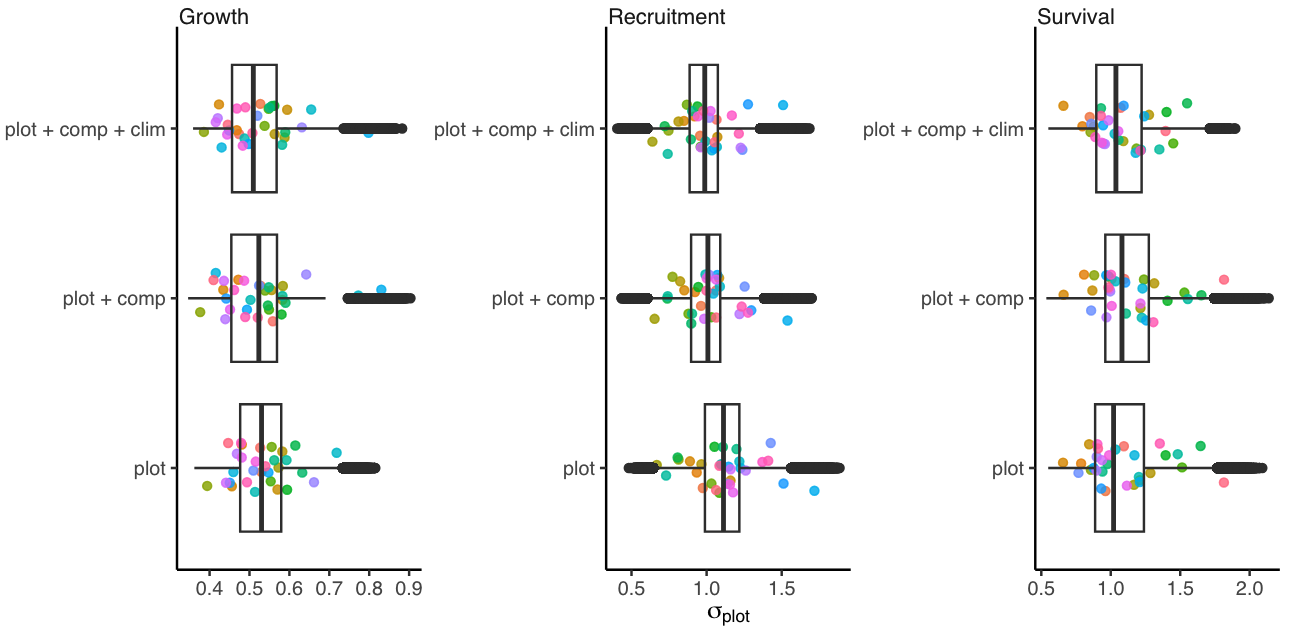
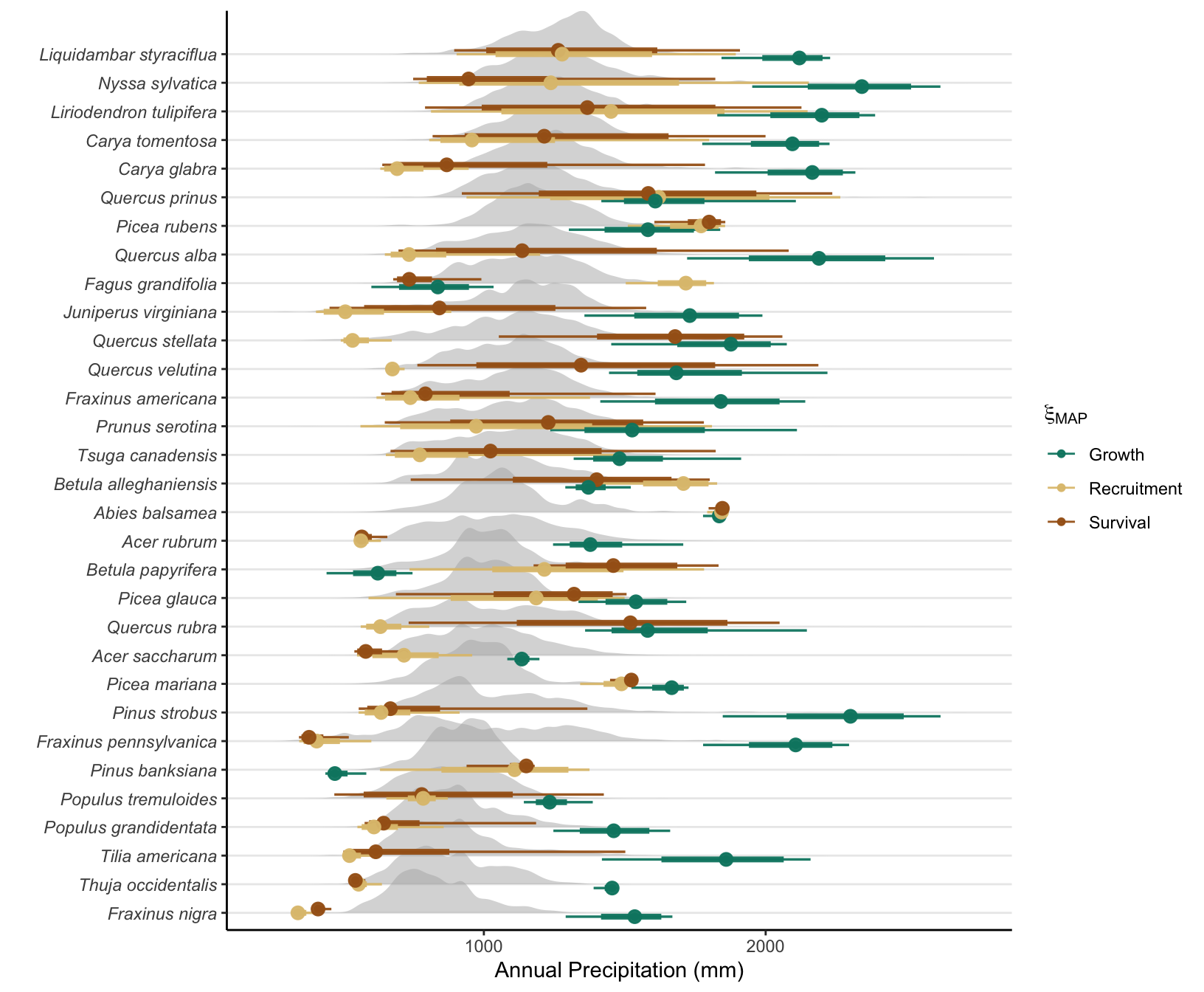
This section describes how the variance attributed to plot random effects changes with increasing model complexity. As we introduce covariates, it is expected that part of the variance in demographic rates, initially attributed to random effects, shifts towards the covariate fixed effects. Therefore, the larger the reduction in variance associated with plot random effects, the more significant the role of covariates in explaining demographic rates. The Figure 1 shows the \(\sigma_{plot}\) change with increased model complexity for growth, survival, and recruitment vital rates.
Model predictive accuracy
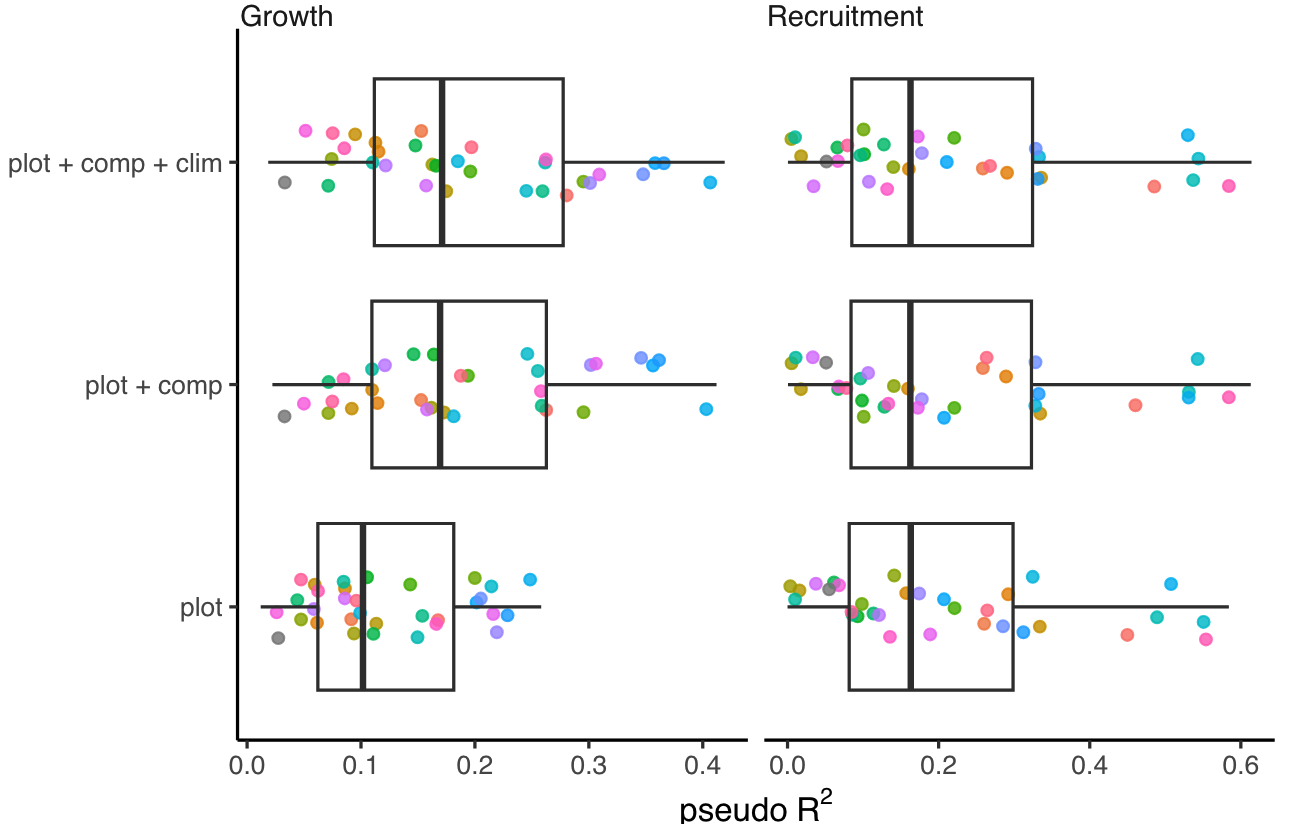
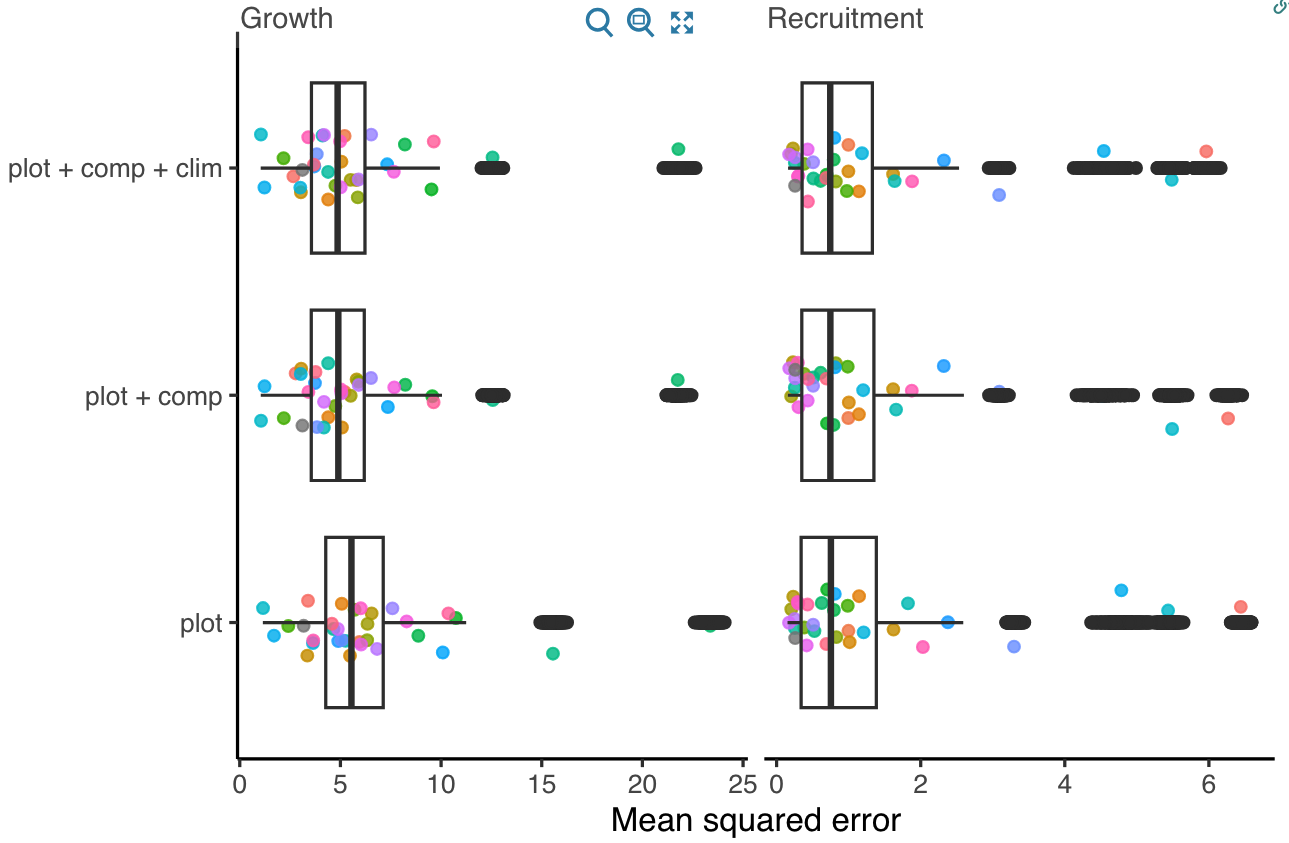
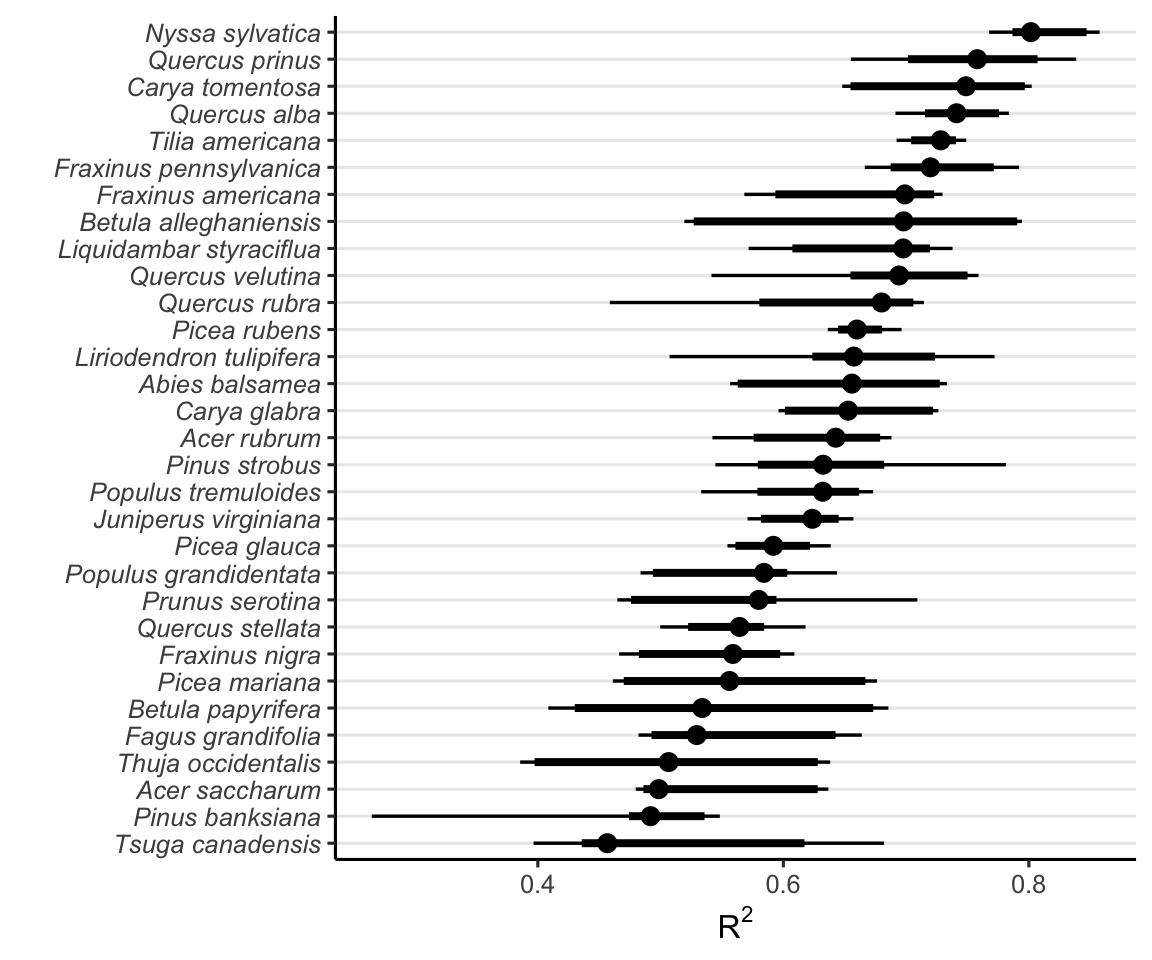
We used pseudo \(R^2\) and MSE metrics derived from comparing observed and predicted values to evaluate the predictive accuracy of growth and recruitment demographic rates. Higher \(R^2\) values and lower MSE indicate better overall model accuracy. The Figures 2 and 3 compare the growth and recruitment models using \(R^2\) and MSE, respectively.
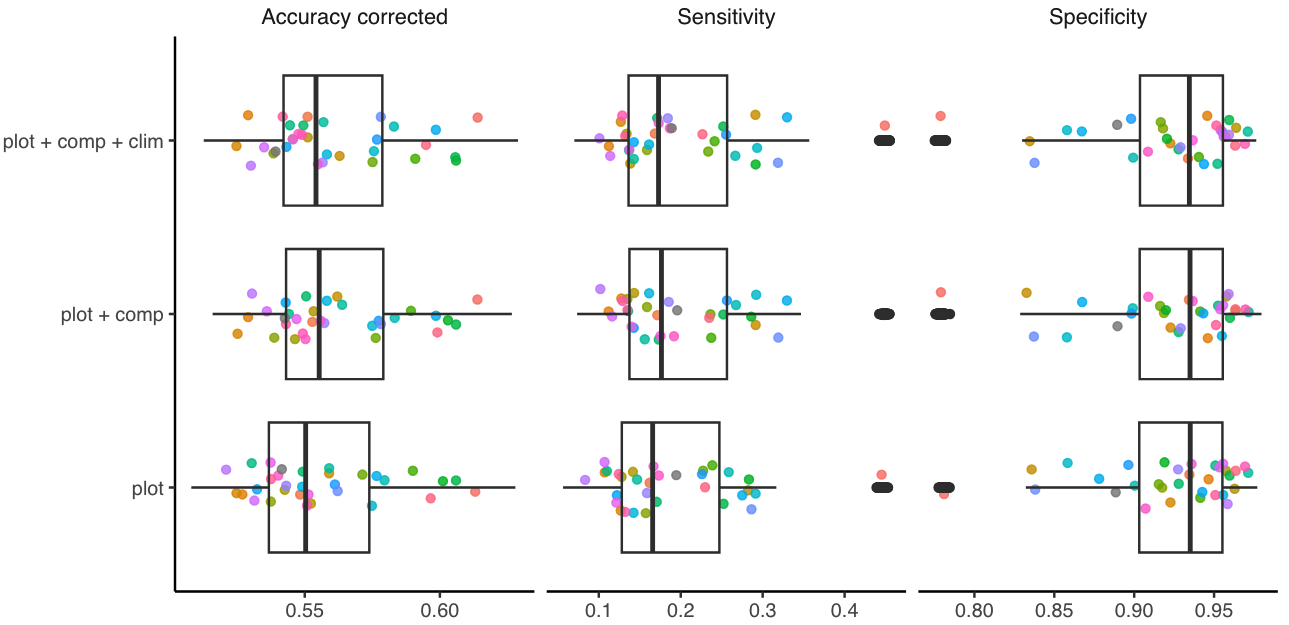
We used three complementary metrics for the survival model to assess model predictions. While the accuracy of classification models is often evaluated through the fraction of correct predictions, this measure can be misleading for unbalanced datasets such as mortality, where dead events are rare. To address this issue, we calculated sensitivity, which measures the percentage of dead trees correctly identified as dead (true positives). We also computed specificity, which measures the percentage of live trees correctly identified as alive (true negatives). The combination of sensitivity and specificity allows us to calculate corrected accuracy, considering the unbalanced accuracy predictions of positive and negative events (Figure 4).
Leave-one-out cross-validation
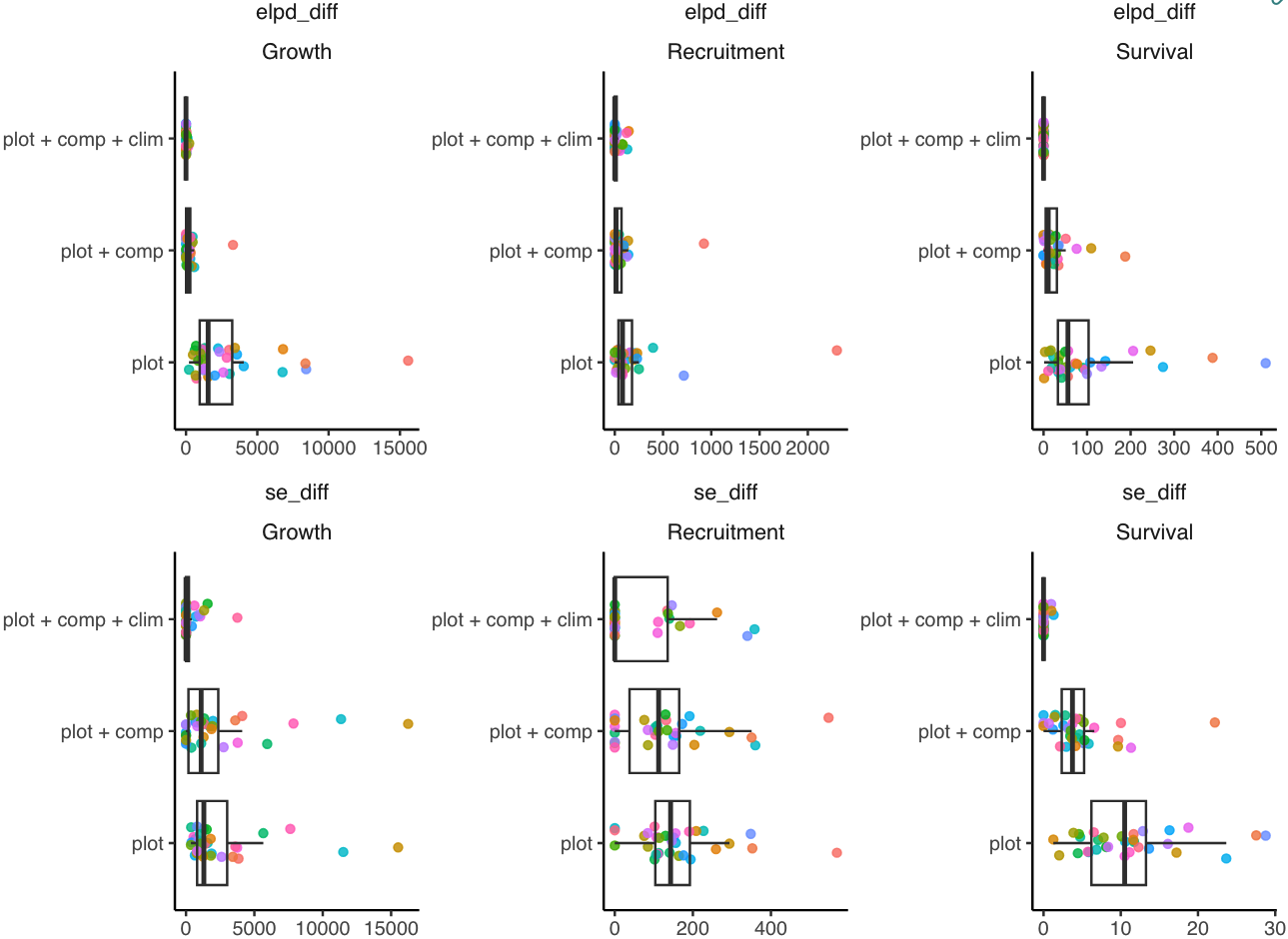
Finally, we evaluated the competing models using the LOO-CV metric (Figure 5), where models are compared based on the difference in the expected log pointwise predictive density (ELPD_diff). In cases involving multiple models, the difference is calculated relative to the model with highest ELPD (Vehtari, Gelman, and Gabry 2017). Consequently, the model with ELPD_diff equal to zero is defined as the best model. In contrast, the performance of the other models is assessed based on their deviation from the reference model in pointwise predictive cross-validation. Given the large number of observations in the dataset, we approximated LOO-CV using PSIS-LOO and subsampling. For each species, we approximated LOO-CV by sampling one-fifth of the total number of observations.
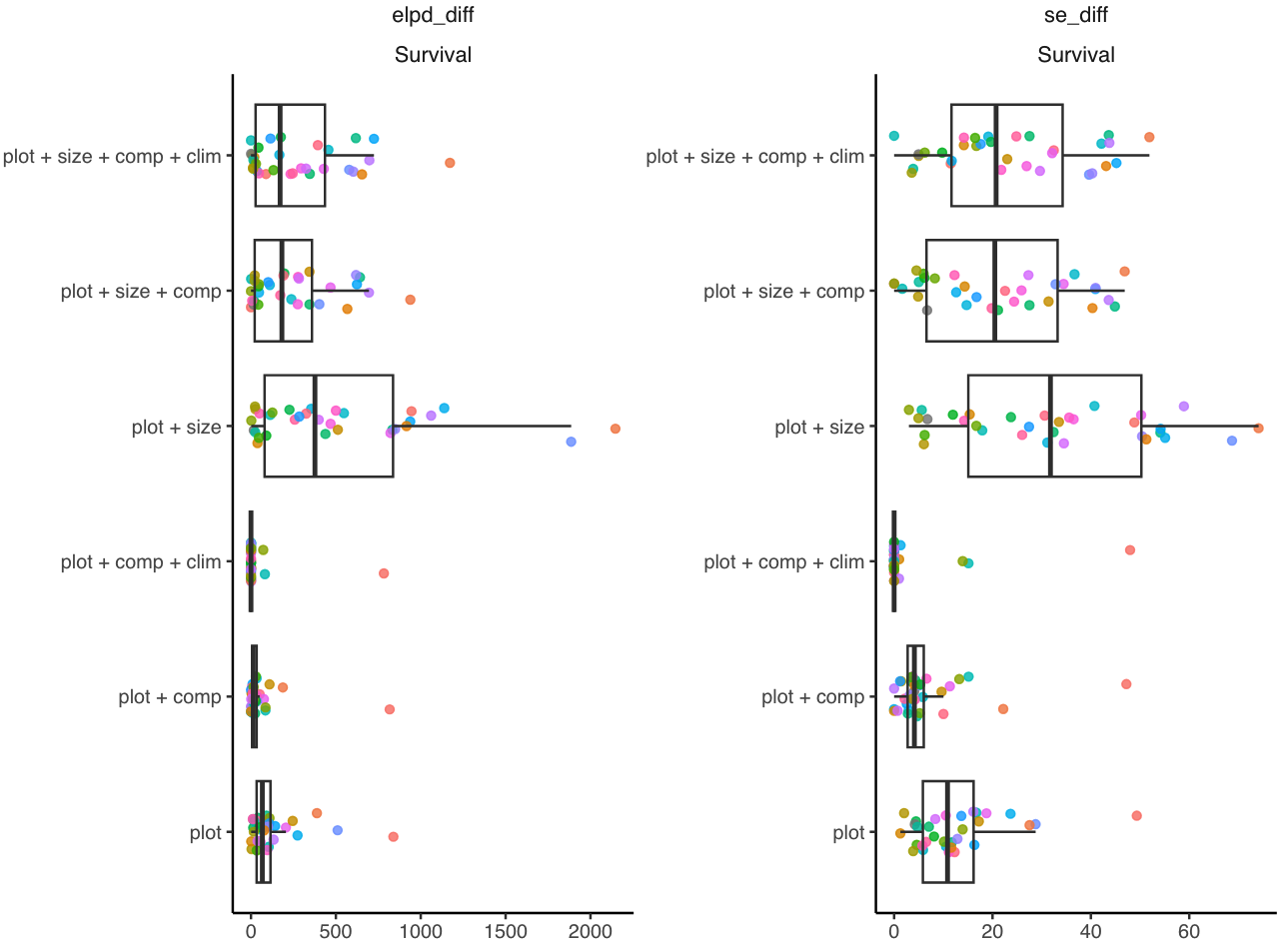
Size effect in survival
We initially incorporated the size effect into the survival models due to the structured-population approach. However, we observed that the effect of size on mortality probability was generally weak and variable among species, with no clear pattern of increased mortality probability with larger individual size. All models that included the size effect performed worse than the null model, which contained only plot random effects (Figure 6).
Conclusion
Our analysis revealed that incorporating competition into the growth, survival, and recruitment models proved more effective in gaining individual-level information than climate variables. The parameter \(\sigma_{plot}\), interpreted as spatial heterogeneity, was lowest in the growth model, followed by recruitment and survival. As the models became more complex with the inclusion of covariates, recruitment exhibited the most significant reduction in spatial variance, followed by growth, with no clear pattern in the case of survival.
Regarding predictive performance, competition contributed more to the overall predictive capacity (\(R^2\), MSE, and corrected accuracy) in the growth and survival models compared to climate variables. Although recruitment had the largest reduction in \(\sigma_{plot}\), it had minimal impact on prediction accuracy.
Finally, the LOO-CV indicates a clear trend where the complete model featuring plot random effects, competition, and climate covariates outperformed the other competing models. Furthermore, the absolute value of the ELPD shows that the growth model gained the most information from including covariates, followed by recruitment and survival models. Consequently, we selected the complete model with plot random effects, competition, and climate covariates as the preferred model for further analysis.
Supplementary Material 2
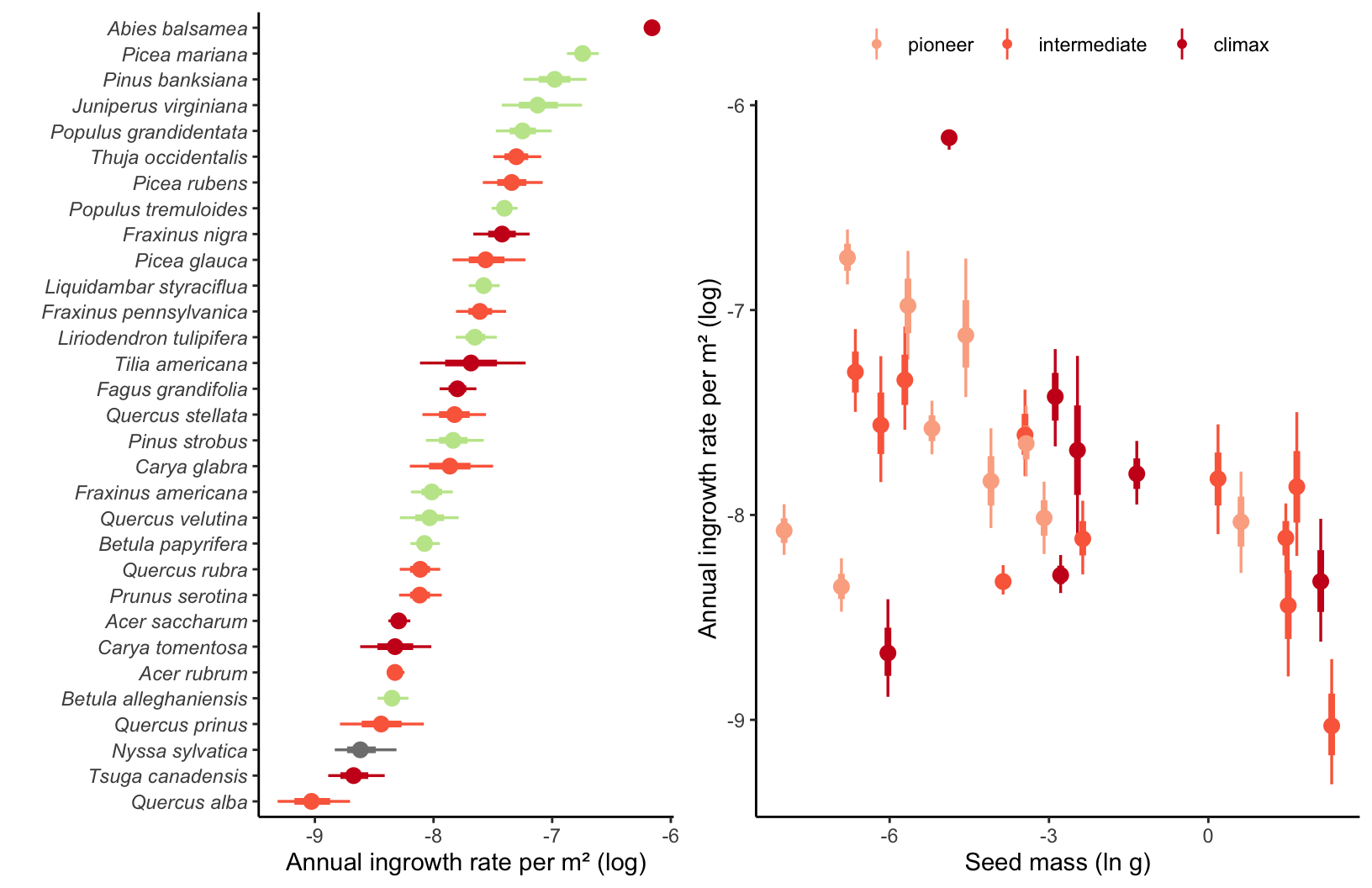
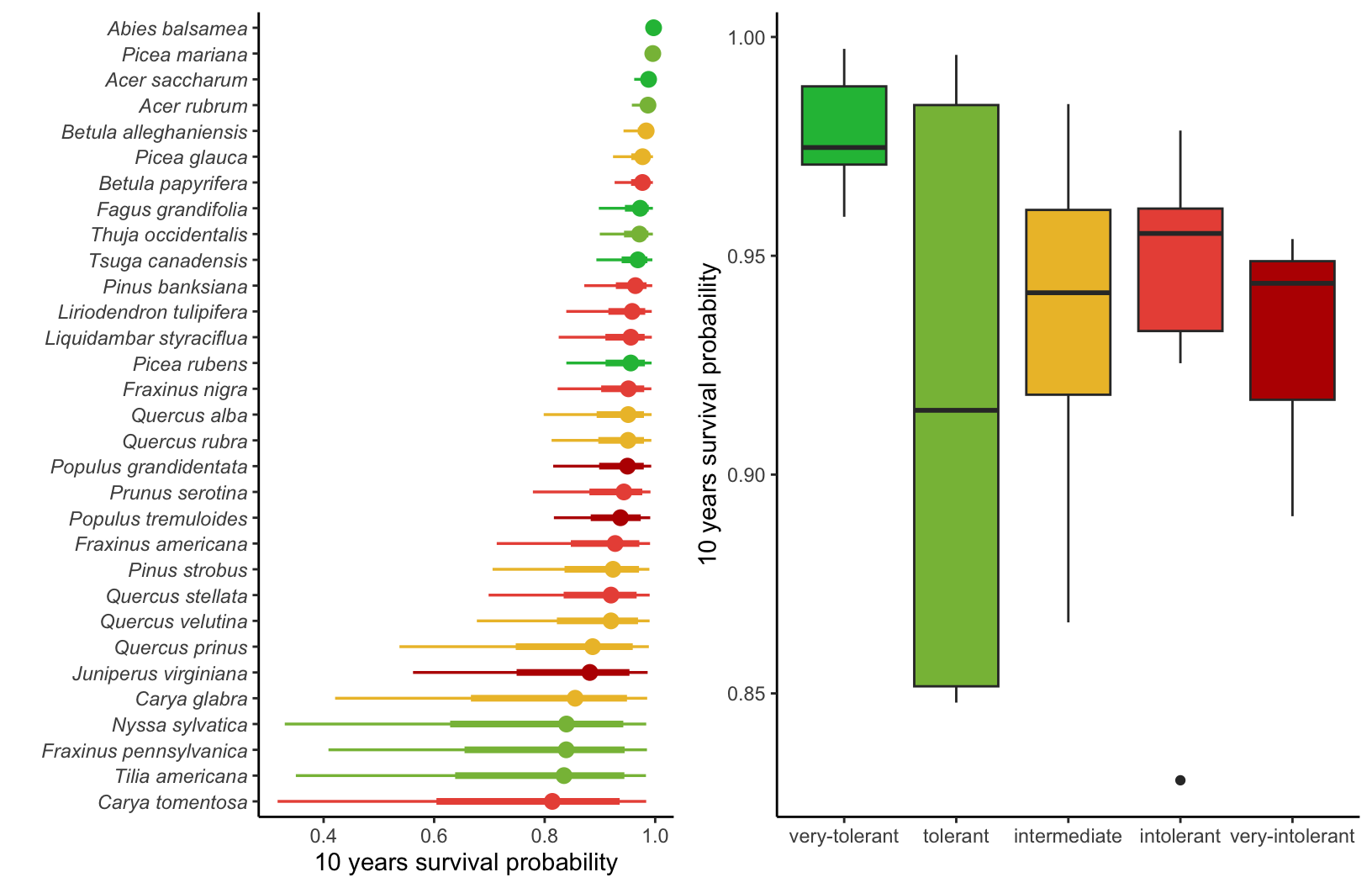
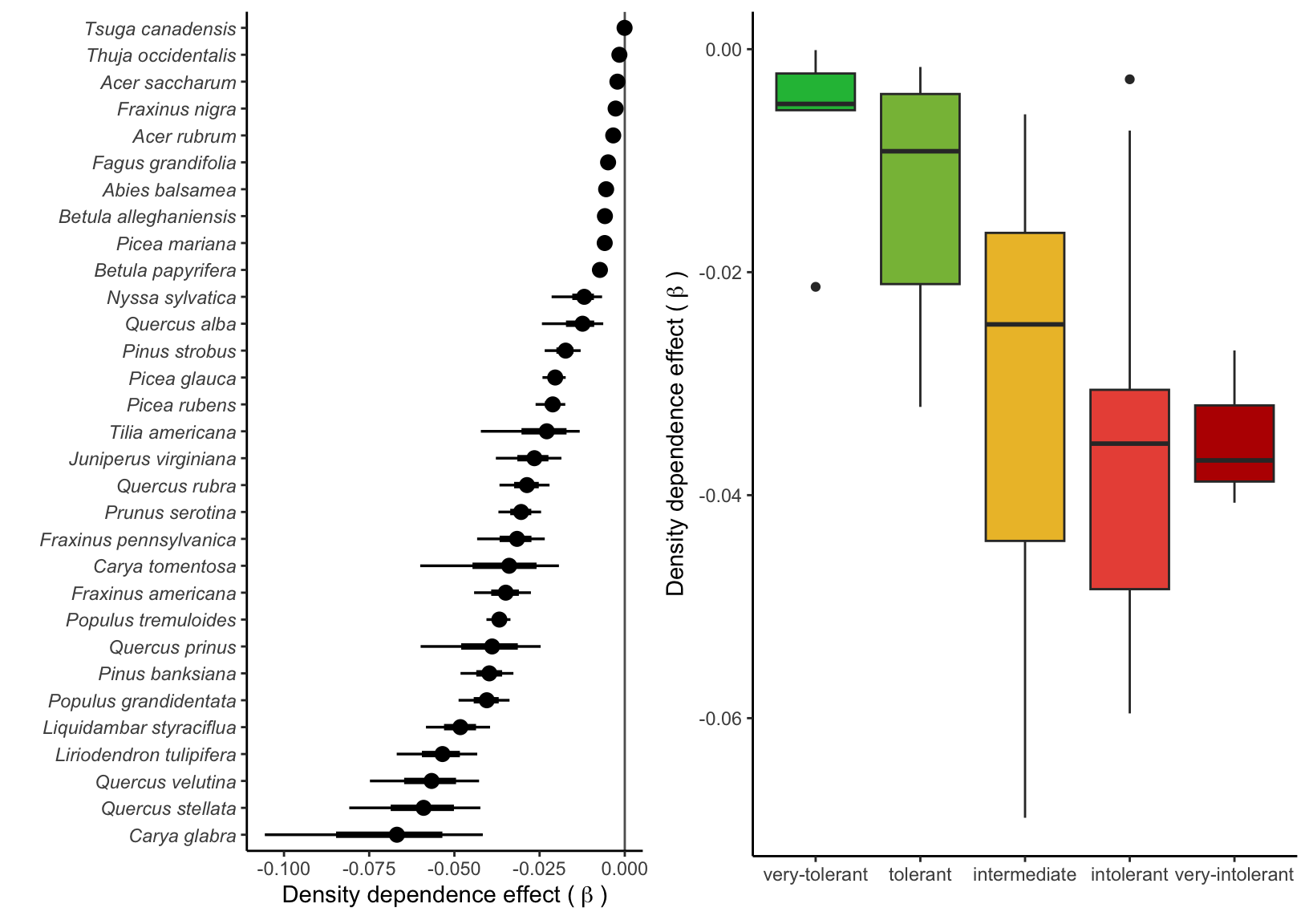
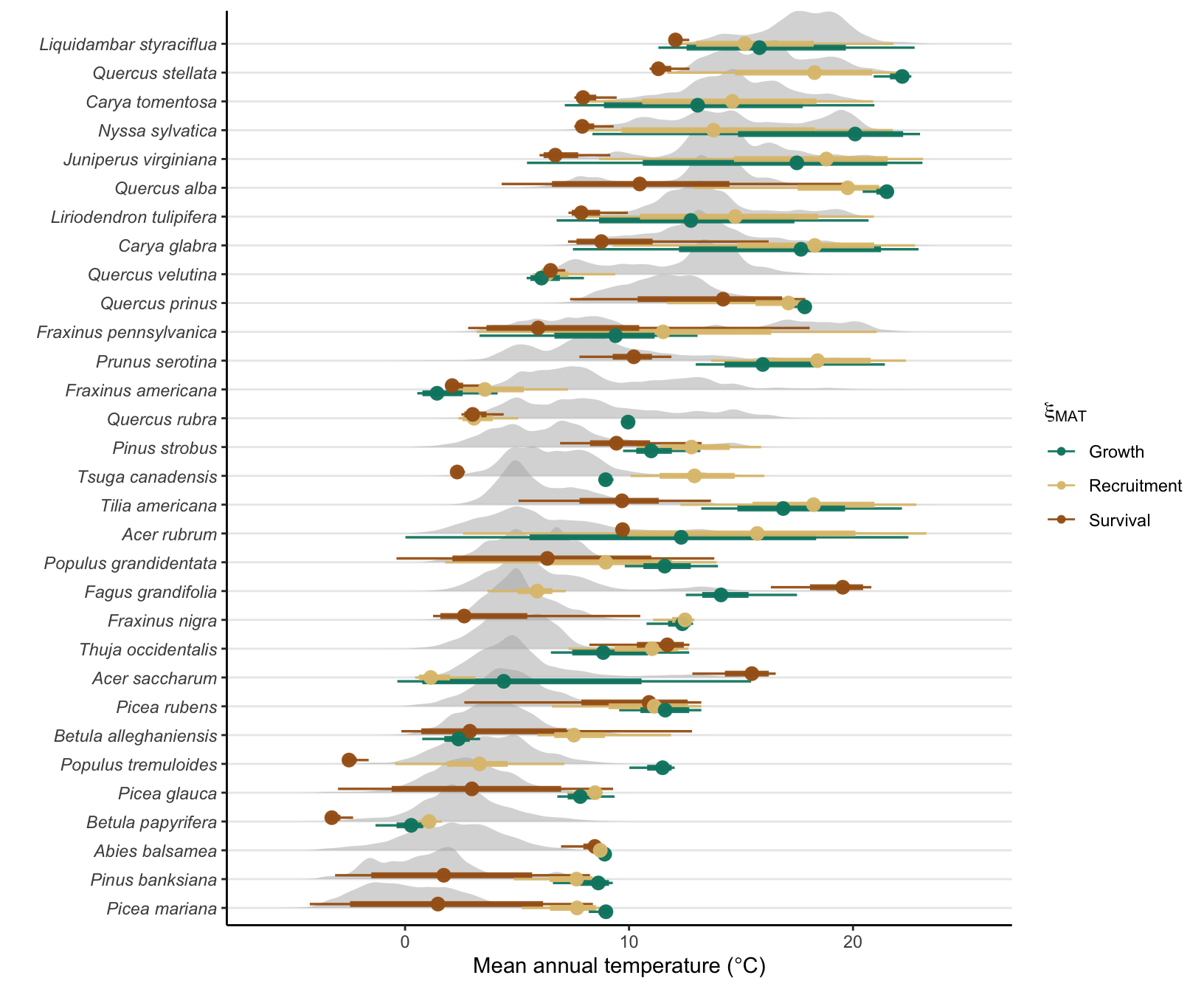
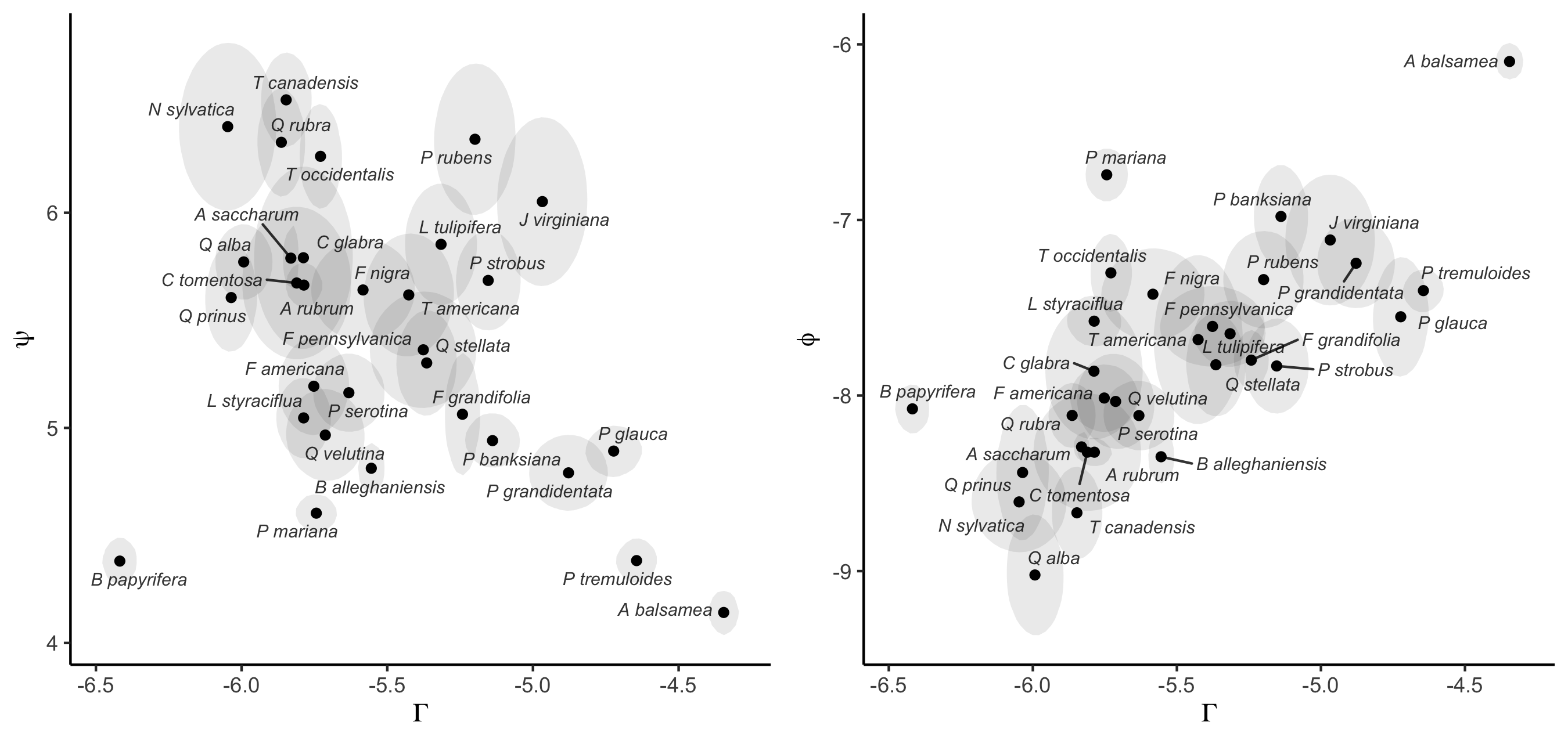
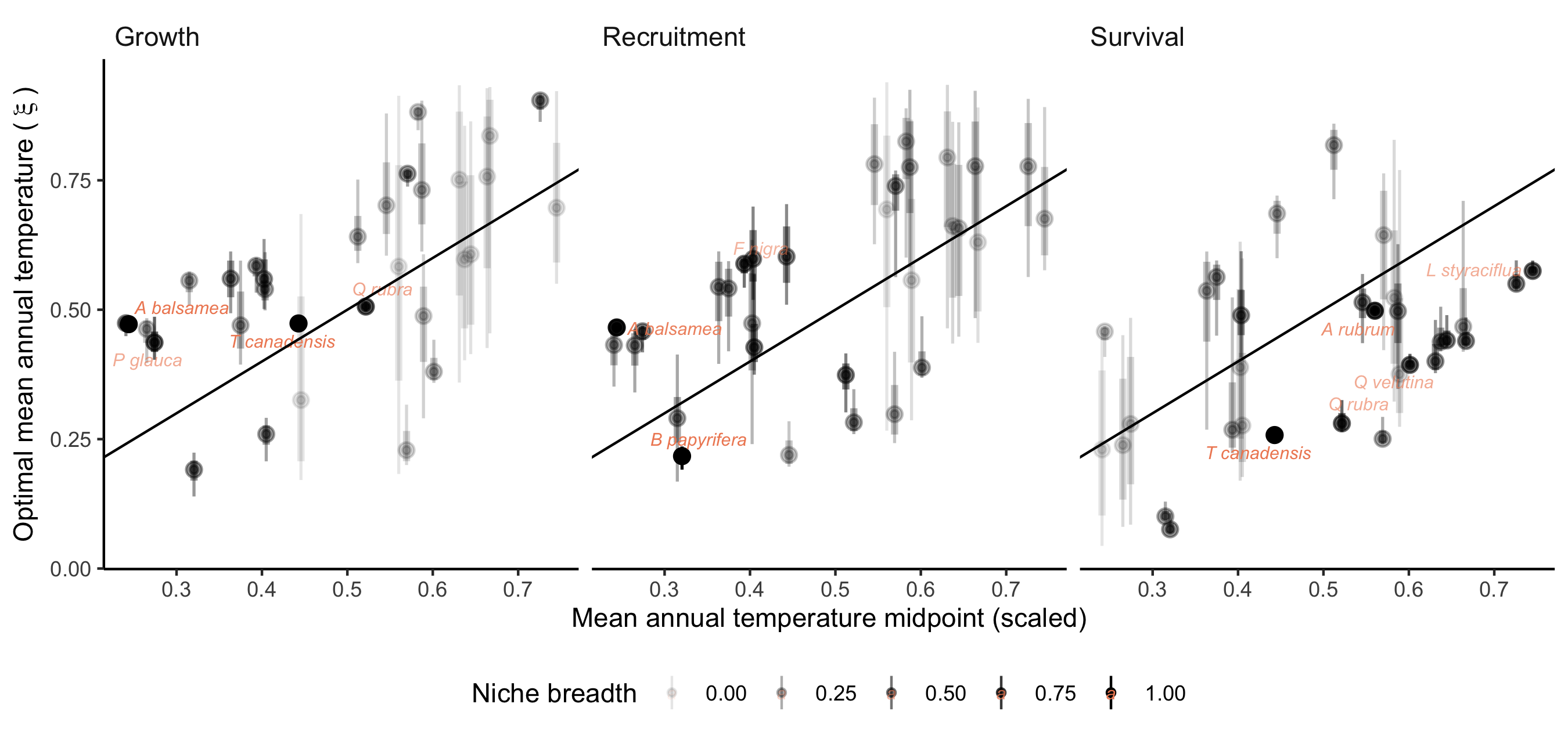
Supplementary Material 3
Sensitivity analysis
Here, we conducted a global sensitivity analysis (GSA) of the population growth rate (\(\lambda\)) with respect to demographic models. Sensitivity analysis uses various methods to decompose the total variance of an outcome into contributions from parameters or input variables. In structured population models, sensitivity analyses involve computing partial derivatives of \(\lambda\) to individual parameters, following Caswell (1978) as:
\[ \frac{\partial \lambda}{\partial \theta_i} \](1)
where theta represents a vector of \(i\) parameters. However, most methods quantify the local sensitivity of each parameter separately while holding all others constant (Saltelli et al. 2019). This approach can overlook the obscure parameter interactions often common in complex models. Furthermore, because of the high dimensionality of IPM due to the large number of parameters, these methods can quickly become computationally expensive.
To address this, we leveraged the efficiency of non-parametric models, such as random forests, for variable importance classification (Antoniadis, Lambert-Lacroix, and Poggi 2021). This approach offers speed and suits our study as it allows us to quantify both sources of variability in \(\lambda\). It accounts for the sensitivity of \(\lambda\) to each parameter and considers the uncertainty associated with the parameters. Therefore, a specific parameter may have higher importance because either \(\lambda\) is more sensitive to it or because the parameter is more uncertain.
We quantified the variability in population growth rate in function of the parameters using an insileco experimental approach. Specifically, we quantified the variability \(\lambda\) for different climate conditions, ranging from cold to the center and up to the hot mean annual temperatures experienced by each species. Furthermore, we combined the climate conditions with a low and high competition intensity. We defined the temperature ranges for each species using the 1st, 50th, and 99th percentiles. The low competition was defined as a population size of \(N = 0.1\), while high competition was set at the 99th percentile of the plot basal area. Precipitation was kept at optimal conditions computed based on the average optimal precipitation parameters among growth, survival, and recruitment models.
For each species, climate, and competition conditions, we computed \(\lambda\) 500 times using different draws from the posterior distribution, setting the plot random effects to zero. The code used for this analysis can be found in the forest-IPM GitHub repository.
Simulation Summary
The final simulation involved a total of 500 draws across species and different conditions. The Figure 20 illustrates the distribution of \(\lambda\) computed using 500 random draws from the posterior distribution of parameters across different climate and competition conditions.
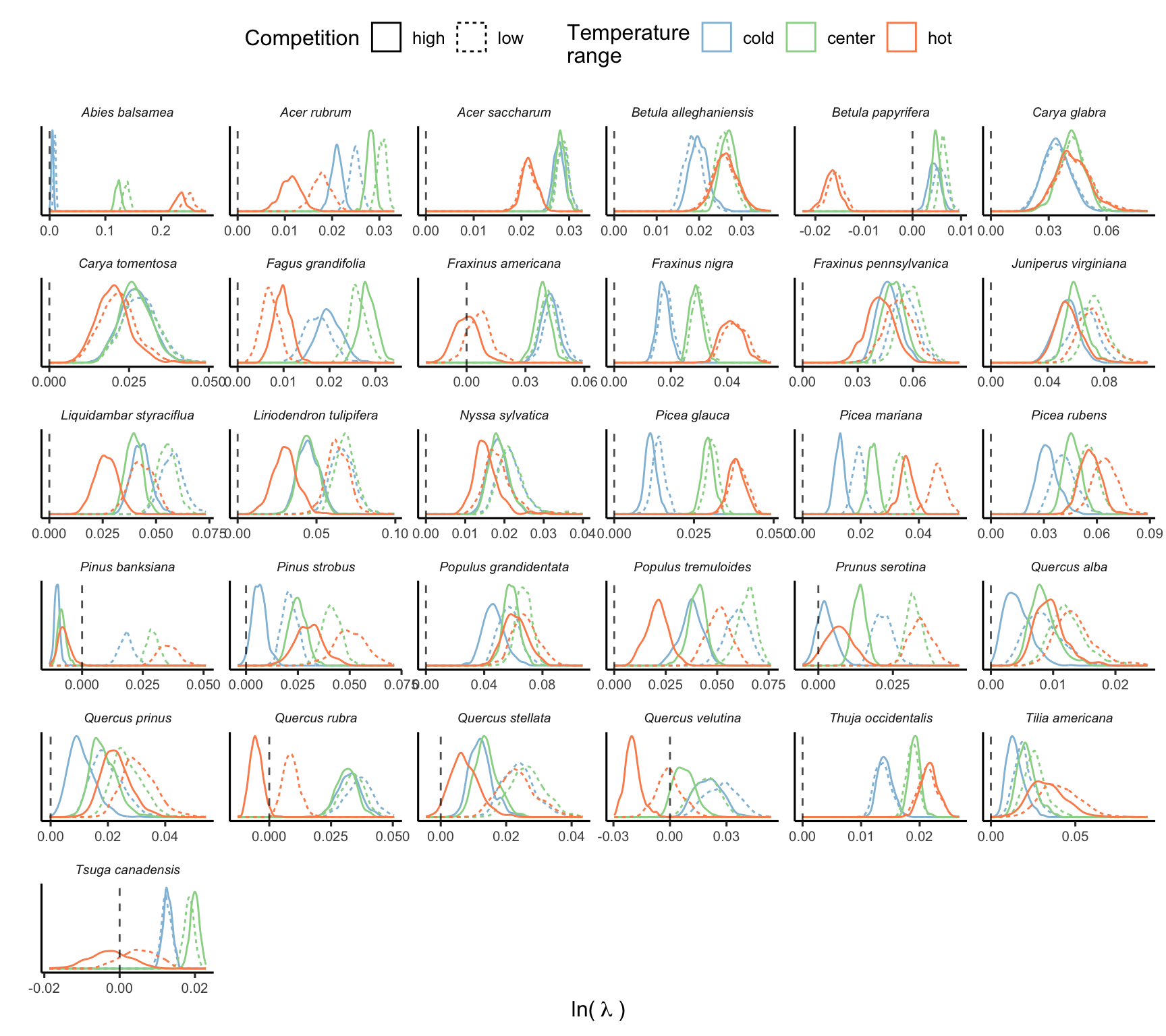
Importance of demographic models
Random forest is a non-parametric classification or regression model that ranks each input variable’s importance in explaining the variance of the response variable. We used the permutation method for ranking variable importance (Breiman 2001). This method measures the change in model performance by individually shuffling (permuting) the values of each input variable. The greater the change in predictive accuracy with shuffling input values, the more important the specific variable will become. This is computed individually for each tree and then averaged across all \(n\) random trees. Finally, we normalized the importance output of each regression model so that they sum to 1. We used the R package ranger with default hyperparameters for fitting the random forest models (Wright and Ziegler 2017).
Figure 21 shows the distribution of \(R^2\) from 20 random forest replications across different climate and competition conditions. These values range from 0.2 to 0.9, with an average value of 0.63 across species and conditions. This variation possibly reflects the uncertainty in the parameters across species.
As our primary interest lies in demographic levels rather than parameter levels, we focus on the combined importance of all parameters for each demographic model. This splits the total importance among the four demographic functions of the IPM: growth, survival, recruitment, and recruited size models. The recruited size model had an insignificant contribution to \(\lambda\), with nearly all random forest models showing a contribution below 1%. Thus, we omitted this model and concentrated on the growth, survival, and recruitment models, which collectively explain over 99% of the variation in \(\lambda\) (Figure 22).
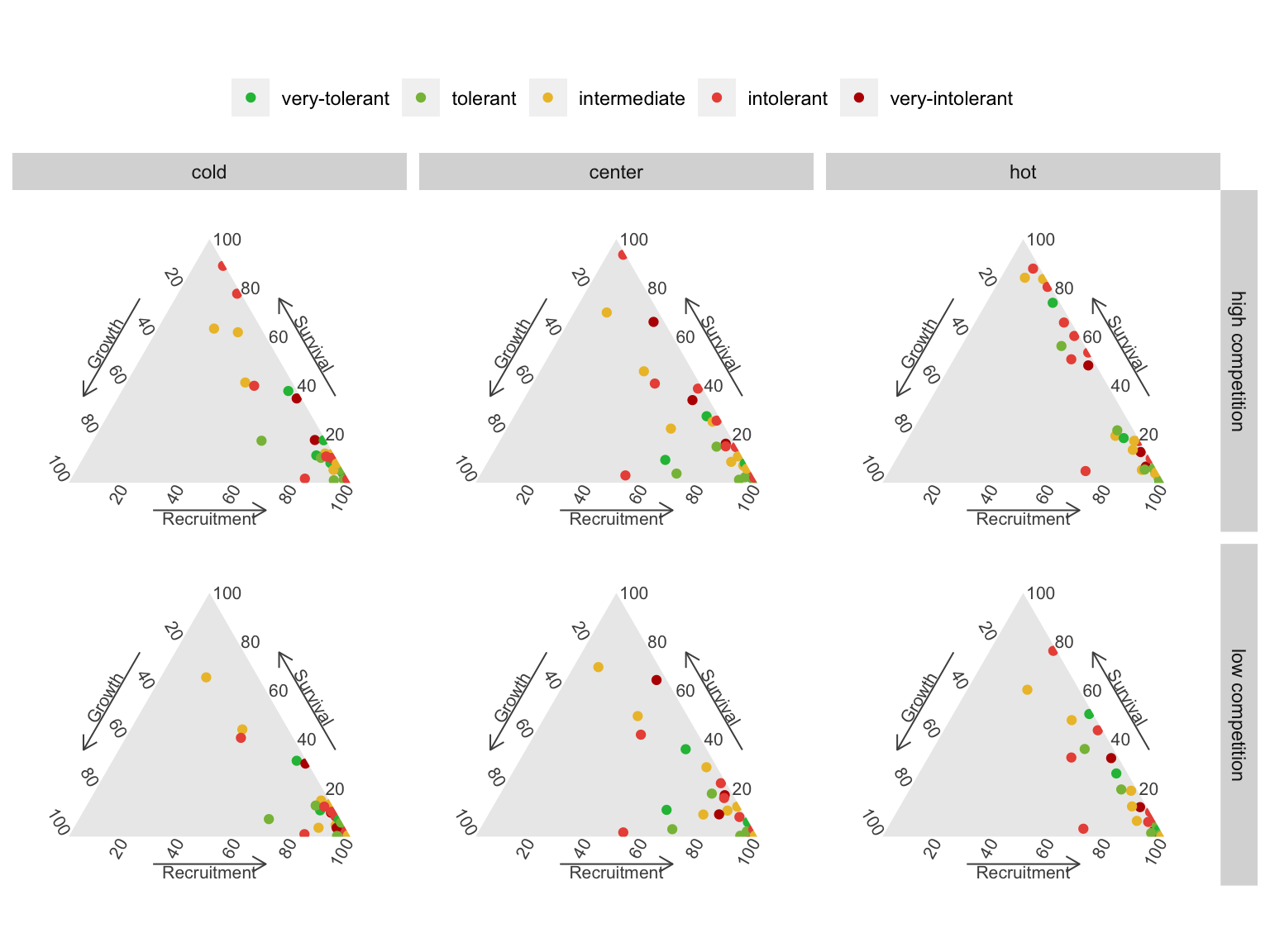
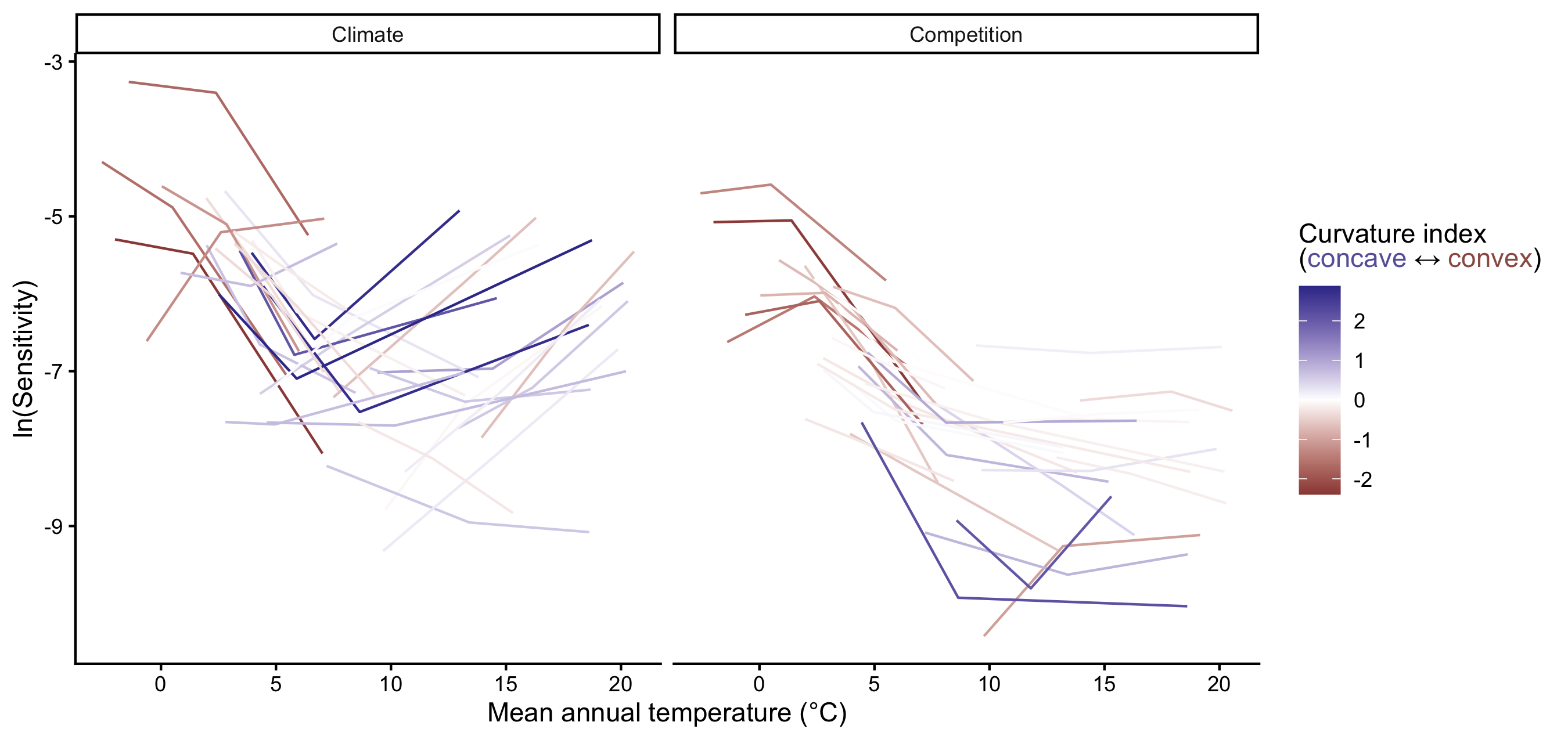
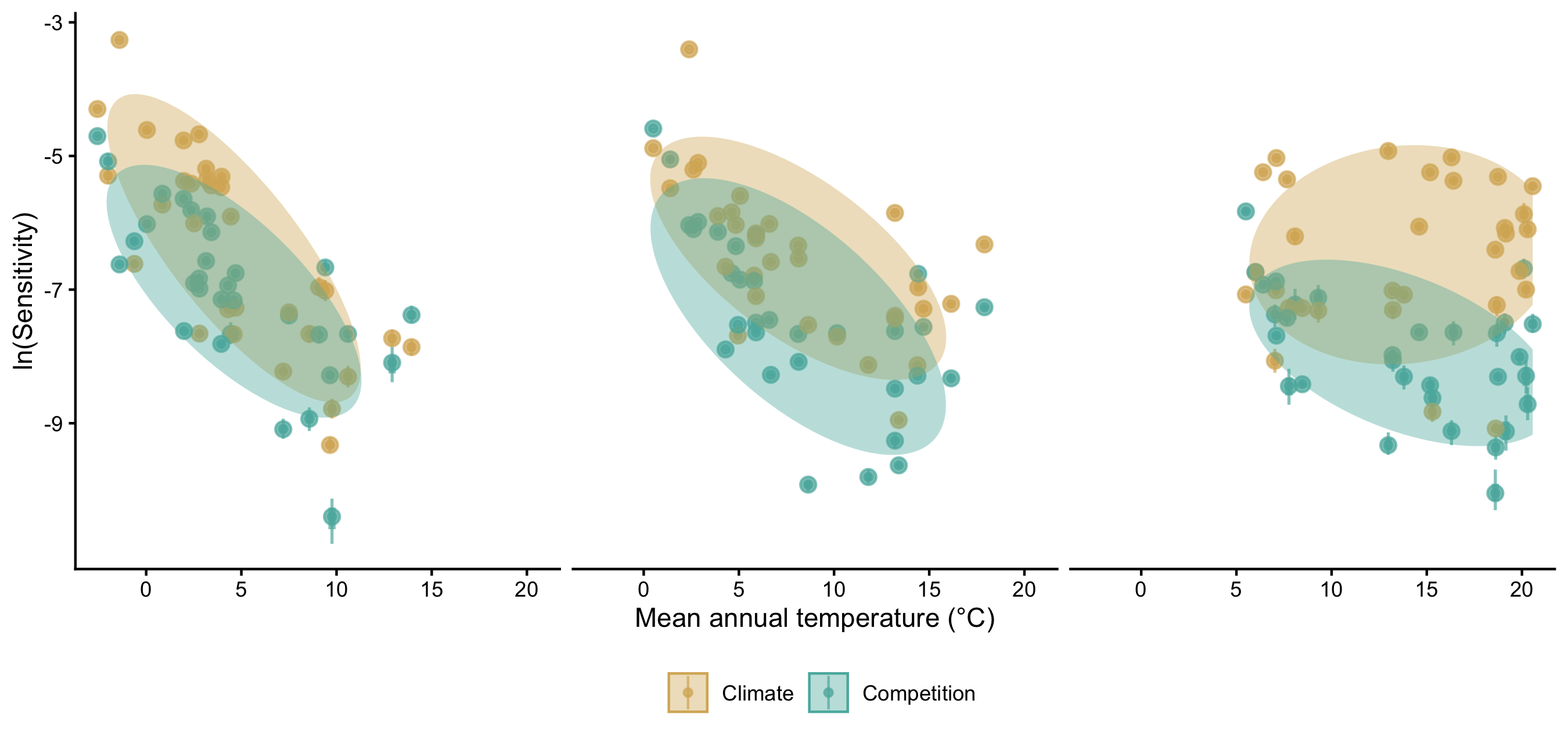
The ternary plots above show the raw importance data from the random forest, which can be challenging to interpret. The key message is that variance in \(\lambda\) is primarily explained by the recruitment and survival demographic models. Furthermore, certain conditions appear to shift the importance from recruitment to the survival model. In Figure 23, we explore the correlation between the importance of recruitment and survival under different covariate conditions.
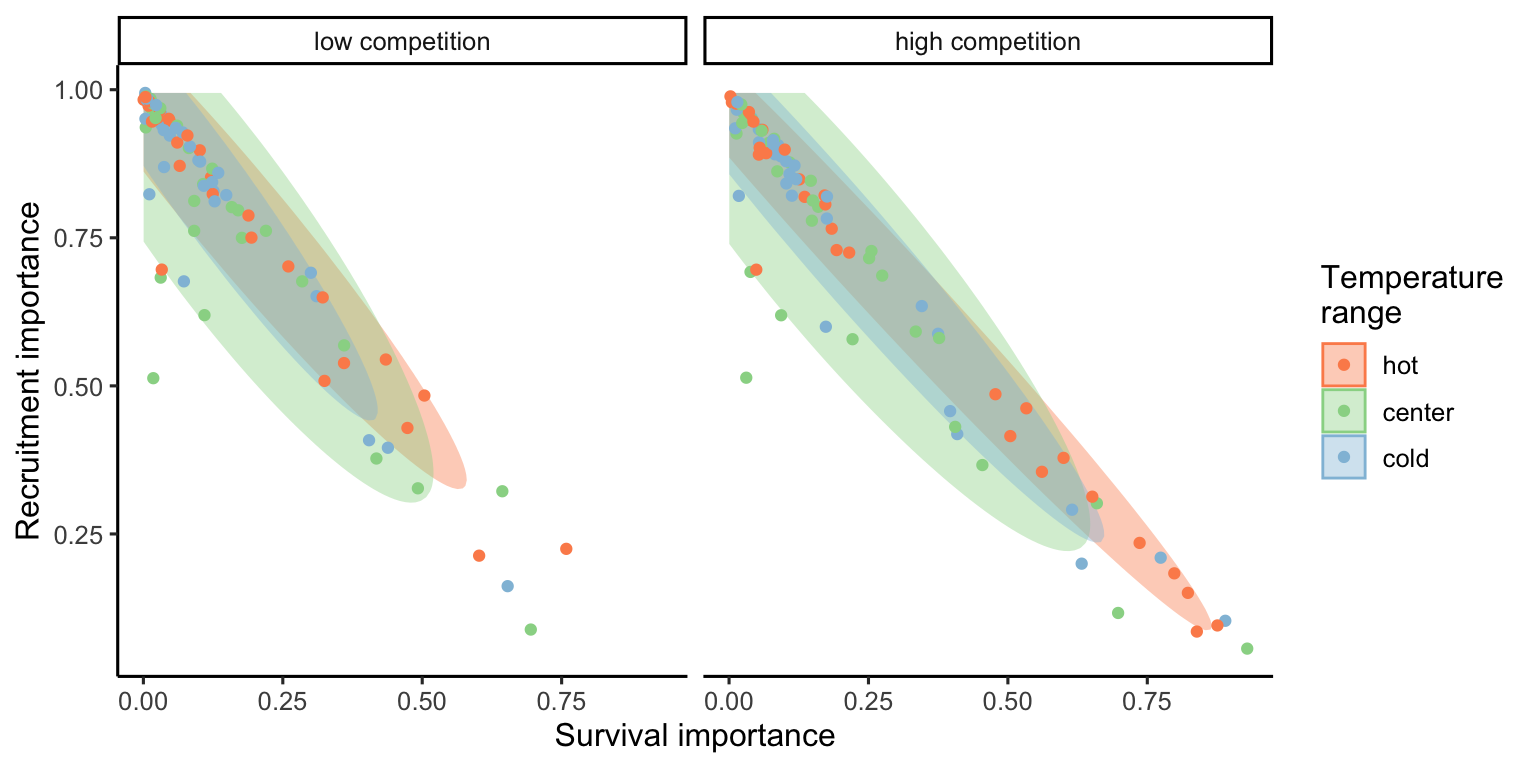
We observe that at low competition, for most species, variations in \(\lambda\) are primarily explained by recruitment. This pattern slightly diminishes as we move from the cold range to the center and up to the hot temperature range. We can observe an overall shift toward the survival model at high competition intensity, especially in the hot temperature range.
Importance of covariates
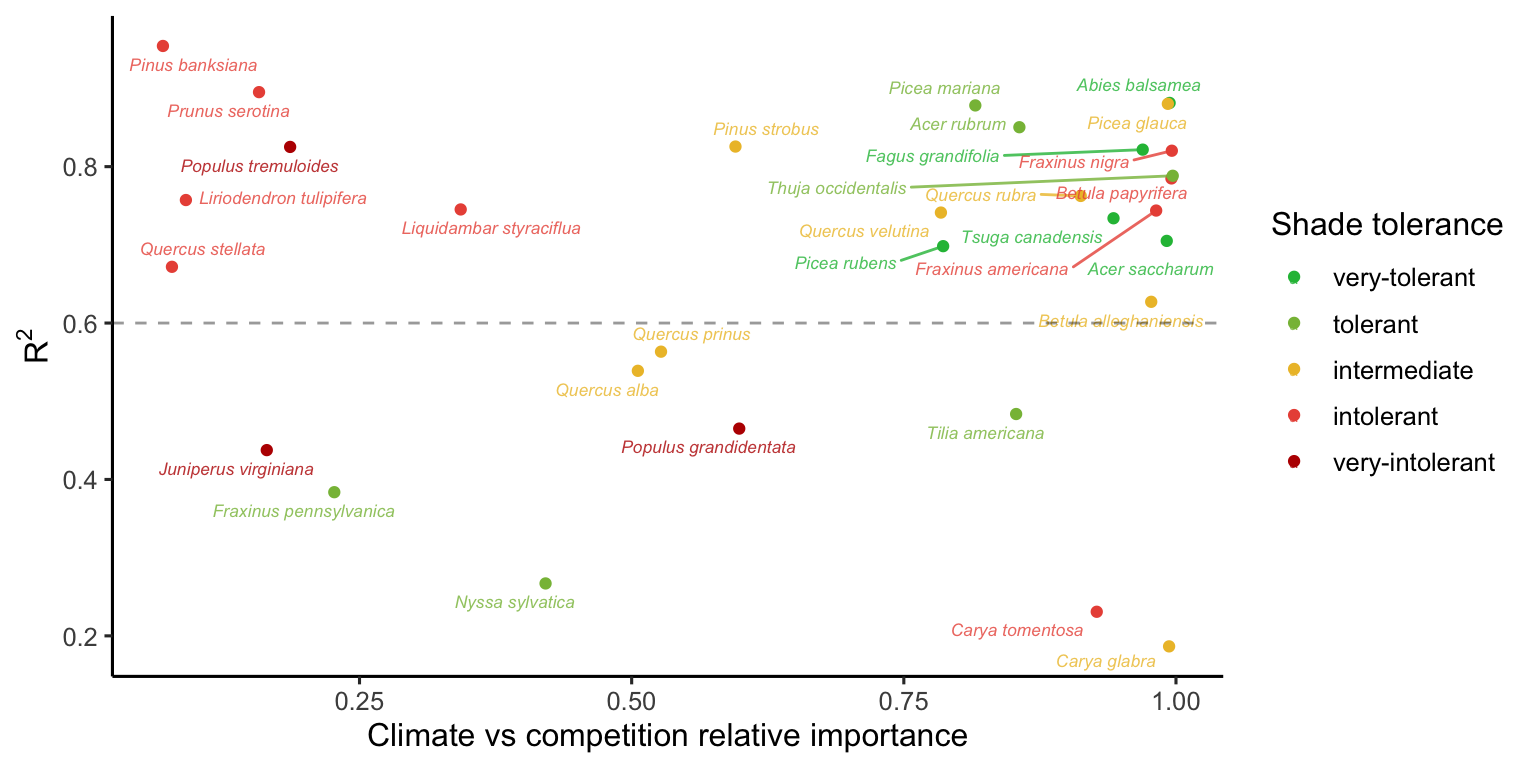
Similar to assessing parameter importance, we also used the random forest approach to evaluate the importance of covariates. For simplicity, we used the same output of the simulations as previously explained, shifting the explanatory variables from parameters to covariates.1 The Figure 24 shows the distribution of relative importance between climate and competition covariates for each species.
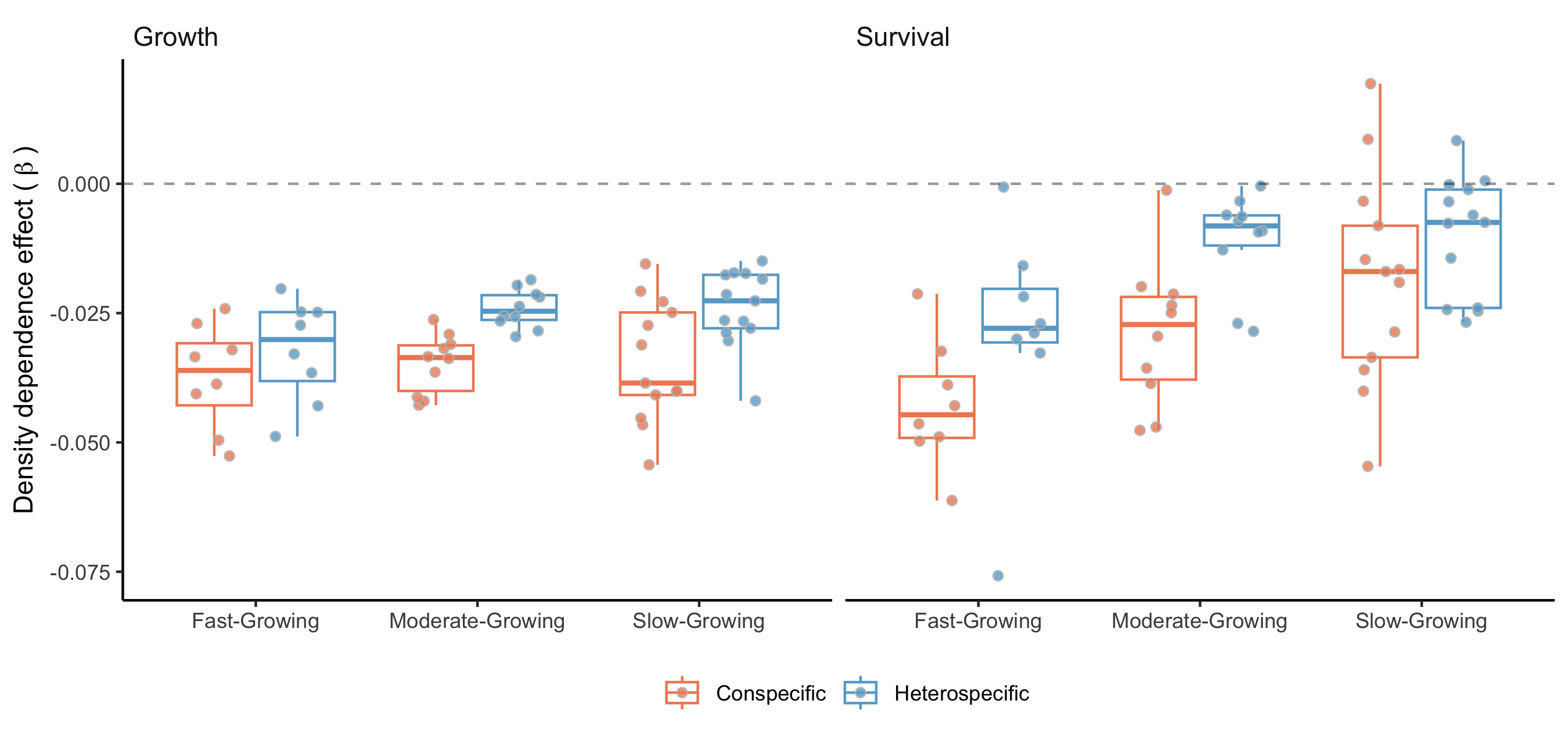
Notes on Conspecific and Heterospecific Competition Effects
In the preceding discussion, we did not specify whether we were considering conspecific or heterospecific competition. For all the results presented in this chapter, the high competition condition was applied at the heterospecific level, while conspecific competition was set to a very low proportion. This choice is based on the standard invasion growth rate metric, or the population growth rate when rare, an important measure for quantifying population persistence (Lewontin and Cohen 1969).
Additionally, we performed the sensitivity analysis with the same conditions, except for changing the high competition from heterospecific to conspecific individuals. We observed that nearly all the variation in \(\lambda\), previously attributed to the growth model, shifted to the recruitment model. Also, the importance attributed to the survival model for certain species at the center and cold temperature conditions shifted toward the recruitment model. Although we observed this shift, the overall patterns remained similar to those discussed earlier. The only exception was the distribution of relative importance between climate and competition (Figure 24), where many species had an increase in the importance of competition relative to climate. These observed differences primarily arise from the high sensitivity of \(\lambda\) to the \(\phi\) parameter.
References
Antoniadis, Anestis, Sophie Lambert-Lacroix, and Jean-Michel Poggi. 2021. “Random forests for global sensitivity analysis: A selective review.” Reliability Engineering & System Safety 206: 107312.
Breiman, Leo. 2001. “Random forests.” Machine Learning 45: 5–32.
Burns, Russell M, Barbara H Honkala, and Others. 1990. “Silvics of North America: 1. Conifers; 2. Hardwoods Agriculture Handbook 654.” US Department of Agriculture, Forest Service, Washington, DC.
Caswell, Hal. 1978. “A general formula for the sensitivity of population growth rate to changes in life history parameters.” Theoretical Population Biology 14 (2): 215–30.
Díaz, Sandra, Jens Kattge, Johannes H C Cornelissen, Ian J Wright, Sandra Lavorel, Stéphane Dray, Björn Reu, et al. 2022. “The global spectrum of plant form and function: enhanced species-level trait dataset.” Scientific Data 9 (1): 755.
Gabry, Jonah, Rok Češnovar, and Andrew Johnson. 2023. cmdstanr: R Interface to ’CmdStan’.
Lewontin, Richard C, and Daniel Cohen. 1969. “On population growth in a randomly varying environment.” Proceedings of the National Academy of Sciences 62 (4): 1056–60.
Saltelli, Andrea, Ksenia Aleksankina, William Becker, Pamela Fennell, Federico Ferretti, Niels Holst, Sushan Li, and Qiongli Wu. 2019. “Why so many published sensitivity analyses are false: A systematic review of sensitivity analysis practices.” Environmental Modelling & Software 114: 29–39.
Team, Stan Development, and Others. 2022. “Stan modeling language users guide and reference manual, version 2.30.1.” Stan Development Team.
Vehtari, Aki, Andrew Gelman, and Jonah Gabry. 2017. “Practical Bayesian model evaluation using leave-one-out cross-validation and WAIC.” Statistics and Computing 27: 1413–32.
Wright, Marvin N, and Andreas Ziegler. 2017. “{ranger}: A Fast Implementation of Random Forests for High Dimensional Data in {C++} and {R}.” Journal of Statistical Software 77 (1): 1–17. https://doi.org/10.18637/jss.v077.i01.
This analysis could be expanded to include more marginal conditions beyond just cold, center, and hot temperatures and low and high competition. However, this would exponentially increase the number of simulations.↩︎